王肇刚(梓弋)阿里云高级技术专家
摘要:业务通过产品技术发挥价值的一个必要条件就是可以在线上稳定持续的运行,这一直是运维人员的终极目标。相信大家在使用天猫、淘宝、支付宝时几乎没有遇到过无法使用的情况,阿里是如何做到的呢?AIOps又是什么?本文主要关注线上业务的研发和运维流程,由阿里云高级技术专家向大家介绍如何将机器学习算法引入运维中的监控和故障分析领域,探索智能运维解决方案。
本文将围绕一下几个方面进行介绍:
一.阿里巴巴故障治理业务流程及挑战
二.智能运维实战
三.AIOps智能运维解决方案
本文主要关注线上业务的研发和运维流程,如今有很多工具可以帮助大家研发协同和部署,但业务通过产品技术发挥价值的一个必要条件就是可以在线上稳定持续的运行。如果业务运行出现故障,业务价值将无法得到保障和发挥。相信大家在使用天猫、淘宝、支付宝时几乎没有遇到过无法使用的情况,这有两个原因:一是阿里的系统稳定性非常好,二是一些局部故障在用户感知之前已经由内部的监控系统发现并解决了。大家一定熟知DevOps一词,而本文标题中的AIOps则是DevOps未来发展的一个趋势。AIOps将机器学习算法引入了运维中的监控和故障分析领域,探索更有效稳定的线上运行效果。
一.阿里巴巴故障治理业务流程及挑战
1. 面临的挑战
首先双十一极具震撼力的数字给阿里带了了巨大的稳定性挑战。

但更大的挑战来自于日常阿里业务的多样和复杂。首先,阿里业务数量巨大,包括2万多名技术工程师,50+ BU,40000+ 应用程序。其次,业务形态差异较大。随着阿里经济体的壮大,出现了许多与传统电商、金融、云计算等不一样的业务形态,例如优酷是文娱,钉钉是社交,还有阿里体育、阿里健康等更多新的业务。业务形态的差异会导致用户行为的多样性。并且阿里国际化业务例如LAZADA、速卖通AE等,也为监控系统带来了许多挑战。最后,业务关联复杂。程序之间需要互相调用,阿里的几万个程序间的调用已经构成了非常复杂的网络,这种牵一发而动全局的情况会给稳定性带来极大的挑战。并且实际情况可能更为复杂,因为除了内部关联,还有外部关联。例如用户可能习惯使用淘宝的搜索框寻找想要购买的商品,若某日搜索功能出现故障,那么便会直接导致淘宝交易量降低。这是因为大部分用户是通过搜索功能进入交易页,出现故障会导致用户找不到其他措施进行交易。应用程序之间的链路复杂和用户行为对业务的影响都会导致业务关联复杂。

因此,阿里需要一个对线上故障进行统一治理的机制。首先,业务故障需要统一的发现,然后跨BU故障协同处理,故障的影响面和根因需要统一收口和推送,最后当确定故障后,第一选择是使用统一的机制快速恢复,只有无法快速恢复的故障才会去分析原因。那么如何在这种复杂的业务流程下实现统一故障处理机制呢?
2. 故障治理业务流程
阿里巴巴全局故障治理流程如下所示:

发现故障后,需要对故障进行定级、通告、辅助定位、处理决策、快速恢复、复盘,以及为了防止下次故障进行的演练。阿里的工程师和更多的内部成员共同协作,通过一个庞大而完备的平台保证该故障处理流程。尽管如此,仍然存在一些人力难以企及的业务痛点。例如,传统的监控系统误报漏报较多。因为业务飞速的变化,监控系统的报警阈值也会飞速变化导致监控维护成本较大。发现故障后需要梳理杂乱的信息才能定位故障。除此之外,还有故障等级定义差异较大、实时决策触发切换难以实现等诸多问题。为了解决这些业务痛点,阿里引入了智能运维AIOps的概念,即将机器学习和一些工程框架引入故障管理流程中。
该故障治理流程的首要目标是实现故障的精准报警。由下图可见,改进的效果十分明显,故障发现的准确率从40%提升至80%,故障通告耗时从5分钟减少为小于1分钟,按照该效率一周可以节约29人时,极大的提升了企业的效率。根因推荐从依赖人的经验改进至系统自动推荐可疑事件,这为大型故障中的指挥调度提供了较好的支持。那么该如何真正实现智能运维呢?

二.智能运维实战
1. 时间序列异常检测
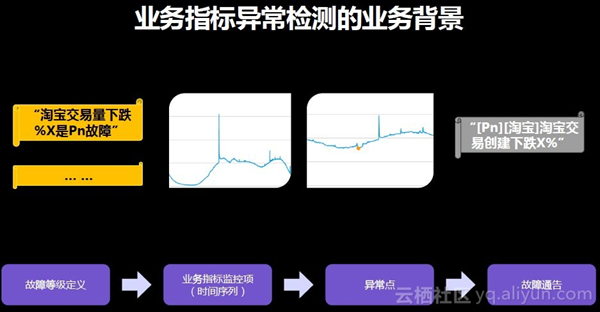
阿里中有成千甚至上万个核心业务指标,例如淘宝的成交量、菜鸟裹裹的包裹量等。如何定义何时出现问题,这其实是一个艰难的行为。因此希望可以将业务上的一个问题通过监控转化为一个技术问题。这里需要澄清的一点是,大家经常需要监控的一些指标,例如集群的CPU利用率、网络流量或者应用程序的response time等,都是系统和应用层面的监控,不是业务层监控。有时系统应用出现问题时业务有可能并不受其影响,例如高可用集群的异地容灾切换保证中,局部集群挂掉可能用户使用并不会出现问题,但另一角度看,可能系统任何问题都没有出现但是业务受到影响,例如运营商的骨干网出现问题,这种情况下仍然需要采取措施来防止流量下降。因此监控的目标需要直达业务结果,业务量下跌即为出现故障,虽然故障可能不是由于系统本身引起,但仍需要发现并定位该故障。如此将一个对业务的监控通过以下流程进行转换,首先对故障进行等级定义,对时间序列的业务指标监控,定位异常点,做出故障通告。
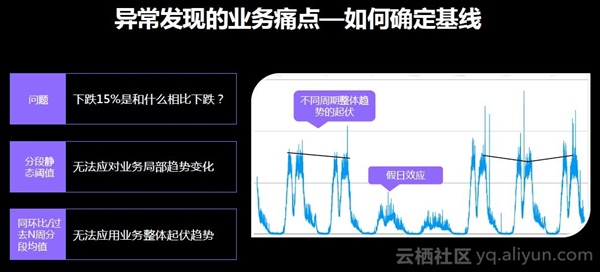
但在实现以上流程中,出现了两大难点。一是无法确定基线。如果判定下跌一定的数值为出现故障,那么下跌的数值该是和什么相比较呢?尤其是高灵敏度的监控基线确定更加艰难。因为业务影响因素众多,受到人的影响尤为明显。如下图中所示,图中每个周期为一天,每天不完全相同,有不同的毛刺和尖刺,由于一些业务变化和营销因素的影响,曲线并不是完全的上扬和下跌,而是有一定的起伏,此时简单的一条横线或者分段的静态阈值已经无法应对业务局部的趋势变化。同比和环比也同样无法应对业务整体的起伏趋势。
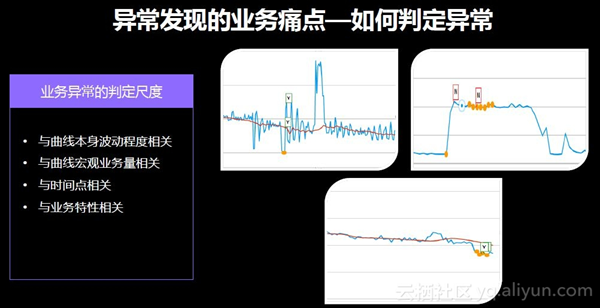
难点二为假设设定了某个基线,如何判定异常。业务异常的判定尺度众多,包括曲线本身波动程度、曲线宏观业务量、时间点、业务特性等。当然也可以不考虑这些因素,那么一天的100条报警中可能65-70条都为误报。
接下来就借助机器学习来解决该问题。这里可以有两种途径供选择,各有优劣。途径一是通过端到端分类,不计算基线直接判断异常;途径二通过回归拟合基线判断异常。阿里采用的是途径二,对业务更可控,拟合出的基线对能否准确的判定异常至关重要。途径二可以通过基于时间序列分解或者机器学习/深度学习实现。阿里业务中,通过基于时间序列分解来进行拟合回归,机器学习/深度学习来解决判断异常。
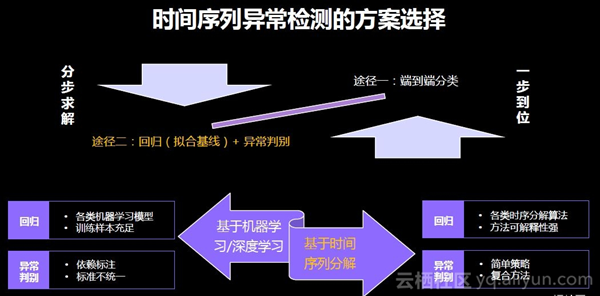
整体算法框架如下图所示。首先对数据进行预处理,包括差值补缺和平滑去噪。然后基于优化后的时间序列分解Seanonal Trend LOESS方法进行基线拟合,滑动平均使曲线平滑。然后结合时间序列分析、机器学习以及特征工程中的各种方法,判断一个时间片段是否需要报警。开始设计时并未确定该算法应采取哪些方法,而是被阿里巴巴各行业的业务、形态各异的数据以及判断标准训练出来的。它的优势在于对各行业的数据有较高的适配性,对非技术性的曲线波动有较强的抗干扰能力。此外,该算法会输出拟合的基线,并且内部系统中可以通过该基线提前100分钟预测趋势,当然距离越近的预测越准确,预测时会将历史波动和局部变化趋势都考虑在内,每个瞬间都会判断这个时刻是否需要报警。出现报警后,可以回溯到该报警的开始时间和结束时间,由此达到整体的报警功能。
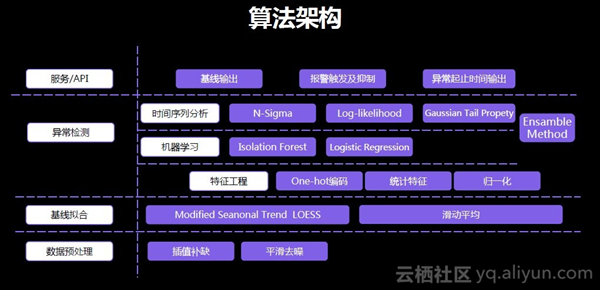
该算法达到的效果十分明显,故障发现准确率由40%提升至80%,故障发现召回率从30%提升至80%,每周因误报而花费的流程操作时间下降了29小时。

2. 智能根因推荐
发现故障后若无法快速切换恢复正常运行则需要深入分析原因。但是在智能根因推荐中也存在众多难点。首先,故障分析定位的范围及边界难以确定。例如,是否需要定位到bug存在于哪段代码,发布的哪个版本,但这个定位范围并不是这里需要的。这里的边界是阿里自定义后的边界。确定边界后,需要通过日志、监控、报警信息及一些集群图表来收集故障定位信息。然后进行定位判断和逻辑决策,判断哪些是出现该问题最可疑的部分并且提出解决策略。在IT行业的技术栈架构下,阿里的应用程序及业务是依靠下图所示的技术基础设施分层搭建出的。

这个框架从一个业务故障出发,从中找出可能导致该故障的应用、中间件或数据库。那么bug具体在哪段代码中并不是这个框架关注的重点。但是这已经可以帮助大家解决两个问题,一是快速了解该问题的影响面,二是快速锁定问题范围。这对业务非常复杂的一些大型企业来说有非常重要的优势和价值。在实现这个框架时,主要按照以下流程。首先,通过时间序列异常检测发现业务异常。然后查询拓扑链路,获取可疑应用及相关上下游应用。接着查询运维数据仓库,获取可疑事件。最后根据故障定位算法,给出可疑程度排序。
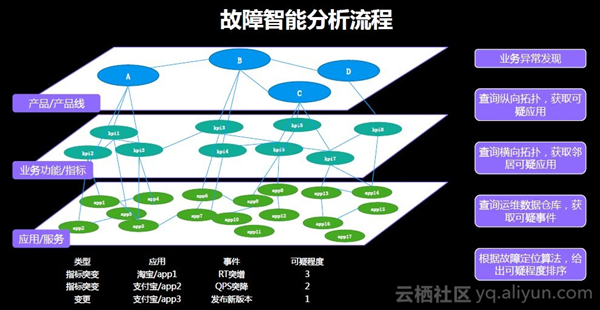
了解故障智能分析流程后,其中仍有一些基础的细节仍需要详细介绍,例如运维数据仓库,数据仓库是指为了解决某一领域的专业问题将一些在线数据作汇聚和整理。但为了故障定位而设置数据仓库,并不只是简单的将可能影响线上业务稳定性的所有数据汇聚。这里的数据仓库是希望实现自动检索与故障相关的事件。因此,运维数据仓库不仅需要汇聚这些数据,也需要耦合对这些数据的组织关系,即metadata元数据,运维中特指CMDB(Configuration Management Database)。相信大家会使用文字的形式记录每次的故障报告,但这些文字不可编程也不可检索,那么运维数据仓库便可以帮助大家实现技术化的、结构化的故障快照。

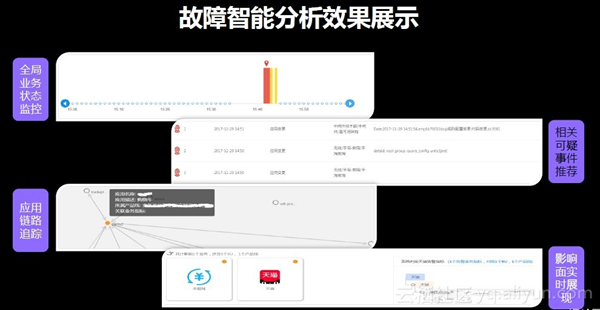
接下来通过一个案例展示其效果。下图中,第一个子图是阿里巴巴全局业务状态监控。空白处表示无异常,出现异常时跳出红色柱状。此时便自动开展上述故障智能分析,推荐相关可疑事件,并且展示相关的应用链路追踪。对某些受众来说,比起故障原因更关心这个故障的影响面,这也会实时展现,包括影响的应用及其功能点列表。
三.AIOps智能运维解决方案
1. 核心功能
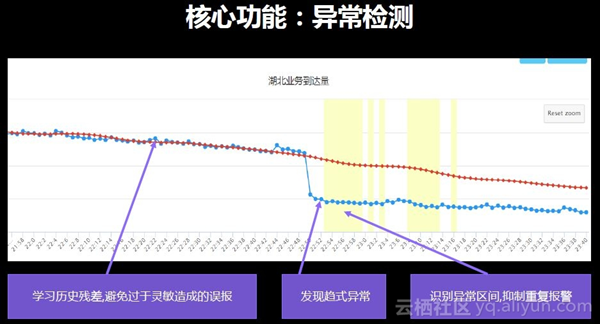
上述内容给大家介绍了在故障发现和原因分析中引入机器学习算法和一些工程框架,这也就是AIOps理念实际落地的产品。阿里希望可以借助阿里云平台孵化AIOps智能运维解决方案,将这个企业产品赋能给客户,进而共同提升企业稳定性。AIOps智能运维解决方案的核心功能有三个。一是异常检测。下图为客户实际测试得出的一个例子,通过预测来判断曲线本应趋势如何,学习历史残差,避免过于灵敏造成误报,即存在某些毛刺是视为无异常情况的。一旦发现明显的趋势偏离,便可以立刻识别和报警,并且在持续偏离的情况下识别异常区间抑制重复报警。
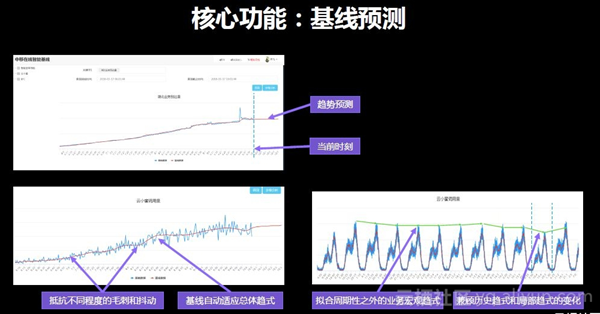
第二个核心功能是基线预测。可以通过回归拟合预测距当前时间100分钟内的趋势,这对处理业务有极大的帮助。如上文所说,该算法通过学习和训练各行业的数据得出,因此即使数据有较多的毛刺和抖动,历史趋势完全不同,该框架都能较好的适应,均方误差较小。直观来说,拟合出的红线一定是大家理想的检测业务下跌的基准,因此为它命名为智能基线。
当出现故障时,还有另一核心功能为多维分析。数据是由分布式系统的日志流式计算汇集,因此数据中会存在某些字段可以进行维度拆解。例如淘宝流量来自于全国各省市各地区,来自于安卓用户和IOS用户,来自于电信或联通。那么流量出现故障时会自动判断这次的流量下跌主要来自哪个省市或应用商,例如是否来自江苏省的移动用户中的安卓用户。这可以帮助运维人员快速的锁定故障对象。

2. 典型场景
在各行业中采集了一些典型场景如下所示:

图一中为爬虫现象,若机器学习到的结果通常显示为该现象,那么就认为这不是业务异常。图二所示现象是否应视为异常如今在阿里内部仍没有定论,对此可以设置一些灵敏度选择,根据不同情况设置为不同结果。图三所示的周期性探测中,大多数业务都以天或者星期为周期,但该业务更多的与月初月末相关,例如信用卡还款、话费流量充值等,因此这种业务是日周期、周周期和月周期的叠加。上文中的算法具备自动探测周期的能力。图四是最经典的探测到交易量的骤然下跌。由此可见,该算法模型可以适配各行业的业务数据。对于底层的系统级数据也有相对应的特定算法。
综上,阿里的AIOps智能运维解决方案有以下三大特点:故障探测、智能调参、自动进化。故障探测中,精准全面报警,鲜有误报漏报,没有人工配置成本,所有流程自动化学习。即使业务发生了巨大的变化,例如阿里的钉钉在这一年中的发展非常迅速,在三个月前业务量可能处于一个量级,三个月后就上升到另一个量级,该算法也会在极短的时间内自动适应,不需要人工修改调整阈值。智能调参是指根据趋势预测的变化自动调节参数。自动学习是指,当大家对是否报警持有争议时,可以采取不同灵敏度报警方案,并且将报警结果反馈回算法,那么该算法会不断学习报警的尺度,优化报警模型,进而提升故障报警的覆盖面和准确性。

本文由云栖志愿小组郭雪整理,编辑百见
