Gopi Kumar,Jiayuan Huang,Nguyen Bach和Luis Vargas
微软首席技术官团队办公室为本文做出了贡献
2022-02-09
1. AI 增强型微软产品和服务
每天,数以百万计的人受益于 Microsoft 在 80 多个企业和消费者场景中提供的强大的大规模基础模型。例如,我们的语言理解功能允许你使用自然语言,使用必应或在 Microsoft Word 中跨 100 种语言查找开放域问题的相关答案。借助相同的 AI at Scale 技术,Microsoft Dynamics 365 提供了相关的答案、见解和员工可以为自己的业务运营采取的操作。
多亏了语言生成,建议的回复使Microsoft Outlook和Microsoft Teams中的即时消息成为更丰富的体验。使用Microsoft Editor,作家可以使用智能工具来制作更精美的散文。我们的语言生成模型还能够了解和综合软件代码。Viva Topics 可在整个组织中自动组织内容和专业知识,使人们更容易查找信息并将知识投入使用,而 GitHub Copilot 则使用 OpenAI Codex 帮助开发人员将自然语言转换为代码。
2. APIs
使用这些功能强大的预训练模型的最简单方法之一是通过托管 API。Microsoft的模型可通过Azure认知服务(Azure Cognitive Services),Azure OpenAI Service和Azure认知搜索(Azure Cognitive Search)作为API端点使用。这使您可以访问模型,而不必担心基础结构和托管详细信息。
Azure 认知服务是基于云的服务,具有 REST API 和客户端库 SDK,可帮助开发人员将认知智能构建到应用程序中。这使您能够构建能够看到、听到、说出、理解甚至做出决策的认知解决方案。
l 适用于语言的 Azure 认知服务为多个下游任务(如机器翻译、情绪分析、命名实体识别和文本摘要)提供 API,从而轻松访问我们的大规模语言模型。
l 适用于语音和视觉任务的 Azure 认知服务为视觉和多模式任务(如视觉问答、图像字幕、对象检测以及语音识别和翻译)提供 API。
l 使用 API(如自定义文本分类、自定义视觉和自定义命名实体识别)针对域或数据微调模型。
Azure OpenAI Service
Azure OpenAI Service目前处于个人预览版中,将为组织提供对OpenAI强大的自然语言生成模型GPT-3的访问,以及Azure的安全性,可靠性和企业功能。一些早期客户正在以创造性的方式使用这项服务。
Azure认知搜索
通过 Azure 认知搜索提供的语义搜索是一种与查询相关的功能,可为搜索结果带来语义相关性和语言理解。包括Igloo Software和Ecolab在内的组织使用它来增强客户和员工的能力。在搜索服务上启用时,语义搜索以两种方式扩展查询执行管道:它在初始结果集上添加辅助排名,将语义上最相关的结果提升到列表顶部; 它会提取并返回标题和答案,您可以在搜索页面上呈现这些内容。
我们正在建立研究和工程之间已经很强的合作,以实现语言突破的新建模技术,并不断将这些技术集成到我们的大规模基础模型系列中。例如,自我监督学习技术的进步使人工智能系统能够从数量级更多的数据、不同的数据语言和不同的数据模式中学习,从而实现更大、更准确的模型。以下是一些令人兴奋的成就。
自然语言理解
我们的大规模基础模型系列从用于语言理解的单语模型开始。微软是第一家在SuperGLUE基准测试中超过达到人类水平的公司,它引入了DeBERTa,DeBERTa被集成到图灵NLRv4模型中。图灵NLRv5模型进一步超越了语言理解能力,该模型最近成为GLUE和SuperGLUE排行榜上的新领导者。图灵ULRv5多语言模型扩展了模型训练以支持多种语言,支持100种语言,在XTREME排行榜上名列前茅,这是评估多语言理解的基准。
虽然这些大规模的预训练语言模型在语言理解方面取得了重大突破,但它们仍然在日常生活中收集的常识知识中挣扎。微软KEAR在常识方面取得了这一突破,在2021年12月的常识测试中超过了达到人类水平。
自然语言生成
2020年2月,微软宣布了图灵自然语言生成(T-NLG),这是当时发布的最大模型,具有170亿个参数。它在各种语言建模基准上的表现优于当时最先进的模型,这些基准涉及诸如总结和问答等任务。这为平台功能奠定了基础,使我们能够训练越来越大的模型。
去年,我们与OpenAI的合作带来了主流的GPT-3模型,这些模型点亮了创新的产品体验,例如通过在Microsoft Power Apps中对话代码来创建无代码/低代码应用程序。然后,我们将这种生成功能扩展到100种语言,使用统一的多语言生成编码器 - 解码器模型(Turing ULG),该模型带来了DeltaLM的研究创新。该模型在大规模多语言机器翻译挑战赛中仍然是排行榜的佼佼者。
2021年,通过微软与NVIDIA的合作,我们宣布了图灵自然语言生成模型(MT-NLG),这是世界上最大的生成语言模型。在模型缩放方面突破极限,它在自然语言任务的主要类别中实现了很强的准确性,包括常识推理,阅读理解,文本预测和语言推断,在零,一和少镜头的设置中,无需搜索最佳镜头。
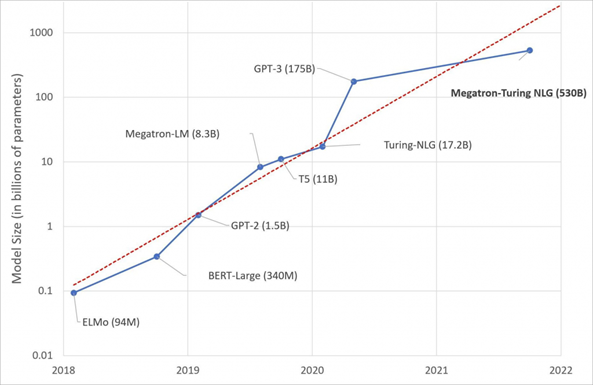
具有大量参数、更多数据和更多训练时间的语言模型可以获得更丰富、更细致的语言理解。此图描述了随着时间的推移,最先进的NLP模型的增加。图表由微软研究院提供。
语言到代码生成
在更具结构化的符号机器语言方面,Codex模型通过将数十亿行源代码和自然语言文本进行训练,将GPT-3从自然语言生成扩展到代码生成,从而为GitHub Copilot提供支持,对程序员来说,GitHub Copilot是一种新的AI,可帮助您编写更好的代码。
模 态
鉴于强大的大规模语言模型取得了巨大进步,我们明白将其他模态整合到我们的模型中至关重要。这些多模式模型可以跨多种输入格式(包括文本、布局、图像和视频)进行联合推理。
我们新的视觉语言模型在NoCaps基准测试中名列前茅,超过了人类基线。我们的图灵布莱切利25亿参数通用图像语言表示模型在94种语言的图像语言任务中实现了出色的性能。它甚至可以在不使用OCR技术的情况下理解图像中的文本,直接识别具有编码图像矢量的类似图像。此外,我们还训练了一个名为Florence V1.0的基础计算机视觉模型,该模型为涵盖40多个基准测试的各种计算机视觉任务提供了最先进的性能。
提高模型功能的一个重要方法是使用名为“专家混合 (MoE)”的集成方法训练具有子任务的专家模型。MoE架构还保留了与模型参数相关的亚线性计算,这为通过扩展数万亿个参数来提高模型质量提供了一条有希望的途径,而不会增加训练成本。我们还开发了MoE模型,以使用DeepSpeed加速的预训练模型系列,DeepSpeed的详细信息可以在下面找到。
这些大规模的预训练模型成为平台,可以通过以符合隐私的方式使用特定于域的数据来适应特定的域或任务。我们将这个基本和领域适应模型的集合称为“AI模型作为平台”,它可以直接用于构建零次/少次学习的新体验,或者通过微调模型的过程来构建更多特定于任务的模型。以类似的方式,你可以在租户范围内使用自己的企业数据对这些模型进行域调整或微调,并在企业应用程序中使用它们来学习业务和产品独有的表示形式和概念。
图灵布莱切利是一个通用的图像语言表示模型,可以用94种语言执行图像语言任务。该模型展示了独特而强大的功能和图像语言理解的突破性进步。照片由微软提供。
Azure 机器学习服务是 Azure 云上的企业级服务,支持端到端机器学习开发生命周期。它为大规模更快地构建、训练和部署机器学习和深度学习模型提供了高效的体验。它通过实验跟踪、模型性能指标收集和行业领先的 MLOps(用于机器学习的 DevOps)实现团队协作。Azure 机器学习服务支持跨所有主要深度学习框架和运行时(例如优化的 ONNX 运行时)进行模型训练和部署。Azure 机器学习服务支持有效使用基础 Azure AI 基础结构和系统优化。
具有数十亿甚至数万亿个参数的大型模型需要大量优化和并行化策略才能进行有效训练。因此,我们开发了一套优化技术,例如零冗余优化器(ZeRO),并自2020年以来将它们开源到一个名为DeepSpeed的PyTorch加速库中。DeepSpeed继续开拓,极度关注大规模模型训练和推理的速度,规模,效率,可用性和民主化。
DeepSpeed中的一些新功能包括使用MoE机器学习技术高效训练稀疏模型的能力,通过课程学习提高数据效率和训练稳定性,为大型模型提供快速高效的分布式推理,以及为广泛使用的运算符(如标准和稀疏转换器)提供的专用高性能GPU内核库。
ZeRO-Infinity是DeepSpeed的另一个功能。它通过将参数和状态卸载到 NVMe 磁盘存储,打破了 GPU 内存壁,使训练模型具有数万亿个参数,使您能够在单个 GPU 上训练大型模型,或者使用几个 GPU 在单个节点上训练大型模型。例如,借助 ZeRO-Infinity,您可以在单个节点上微调 GPT-3 大小的模型,从而创建在更适度的硬件上训练非常大的模型的能力。使用DeepSpeed优化,我们的内部生产工作负载已经看到了2到20倍的模型比例和大型模型的快速训练。
ZeRO-Infinity 通过以下方式有效地利用 GPU、CPU 和 NVMe:1) 在所有数据进程中对每个模型层进行分区,2) 将分区放置在相应的数据并行 NVMe 设备上,以及 3) 协调计算数据并行 GPU 和 CPU 上分别向前/向后传播和权重更新所需的数据移动。
ONNX运行时(ORT)是训练和推理优化的另一个维度,我们编译深度学习模型执行图,并通过运算符和高效GPU内核库的融合来确定最佳执行。现在,您可以将 ONNX 运行时的图形级执行优化和 DeepSpeed 中的算法优化相结合 — 使用 Microsoft 为 PyTorch 开源贡献的 Torch ORT 模块 — 使训练更加高效。在我们的基准测试中,我们注意到,当DeepSpeed和ORT结合使用时,微调Hugging Face模型的性能提高了86%。
我们很高兴看到一些领先的框架和库,如PyTorch Lightning,FairScale和Hugging Face,采用DeepSpeed和ORT。DeepSpeed也是微软与NVIDIA合作的核心,该模型是世界上最大的语言模型,一个5300亿的参数模型。像BigScience Workshop这样的计划利用DeepSpeed技术,通过基于全球开放社区的方法构建大规模的多语言多任务模型。
几年来,ONNX 运行时一直支持在 CPU 和 GPU 上进行推理,通过内置优化提供高达 17 倍的加速。我们扩展了优化,以涵盖云和基于 PC 的边缘设备之外的模型部署,包括适用于移动设备的 ONNX 运行时和用于 Web 的 ONNX 运行时,用于在 Android 和 iOS 设备上本地或在内存和存储占用空间较小的 Web 浏览器中运行推理模型。
我们还开发了其他算法创新,例如大语言的低秩适应(LoRA),这有助于进一步减少内存占用,同时微调大型模型,只需重新训练一小部分参数(在某些情况下低10,000倍),而不是微调过程中的所有参数,从而节省了3倍的计算需求。同样,LoRA在部署基于共享基本模型参数的同一大型预训练模型的微调模型的几个独立实例时很有用,并且每个实例或下游任务都有一小部分参数。
这些创新使计算资源的有效利用成为可能,从而能够以更少的资源进行训练,并允许研究人员尝试更大的模型,以提高各种任务的最新技术。
最后,构建大规模 AI 需要可扩展、可靠且高性能的基础架构。Azure 在公有云中为各种规模的 AI 工作负荷提供一流的超级计算基础结构。它支持从单个GPU到旗舰NDv4系列虚拟机的流行框架(如TensorFlow,PyTorch等)的GPU加速,该虚拟机提供八个NVIDIA A100-80GB GPU,该GPU完全由计算机内部和机器间最快的网络互连。该系统目前被评为世界上最快的超级计算机的前10名,并且是该名单上第一个基于公共云的系统。除了这些 AI 计算资源之外,Azure 还提供了 AI 训练工作负荷所必需的各种存储和网络解决方案。

照片由微软提供。
人工智能模型的规模不断扩大,实现了曾经看似不可能的功能,并产生了最先进的基准记录。硬件和基础设施能力将继续保持增长的步伐。随着MoE等技术在工具和效率方面的进一步成熟,我们将看到大规模AI的更多进步,包括在不同数据集上训练的单个模型的增加,以大规模执行多个任务。
我们在大型语言模型中看到的同样的能量已经蔓延到其他领域,比如计算机视觉、图学习和强化学习。模型本质上将越来越多模态,学习音频、图像、视频、语言、结构化表格数据、图形数据和源代码组合的多种输入格式的表示,以提供更丰富的体验。
我们将继续为不同渠道的客户和合作伙伴提供更多这些强大的 AI 模型作为平台,无论是通过 Microsoft 产品组合的集成体验,还是通过 Azure 认知服务、Azure 语义搜索和新的 Azure OpenAI API 等易于使用的 API。此外,我们将继续与学术和研究界合作,通过图灵学术计划,进一步改进我们模型的训练和使用中负责任的人工智能方面。
我们仍然致力于通过开源将这些模型作为平台共享这些模型的关键构建块。我们在 DeepSpeed、ONNX 运行时和 Azure 机器学习中的训练配方方面不断创新,以推动效率的界限来训练和服务模型,并将模型的规模增加到数万亿个参数。我们将继续使训练或适应越来越大的基本模型并将这些模型部署到云中的访问和能力民主化。
以云技术为动力的基础设施、机器学习加速软件、平台服务、建模等创新融合,为加速AI创新创造了完美条件。这将改善对这一强大技术的访问,使每家公司都成为人工智能技术公司,并帮助您更有效地实现业务目标。我们期待看到您可以使用大规模 AI 技术堆栈构建的令人兴奋的应用程序和体验。
